While operating six AD5050 “Myxa” ESCs in a long duration test setup, we discovered a severe failure condition.
The ESCs are operated via Cyphal (Telega 1.0 firmware), receive velocity setpoints via the setpoint_velocity port at 20 Hz, and (should) run uninterrupted for days and potentially weeks. Each device has its own setpoint index for the subscription array.
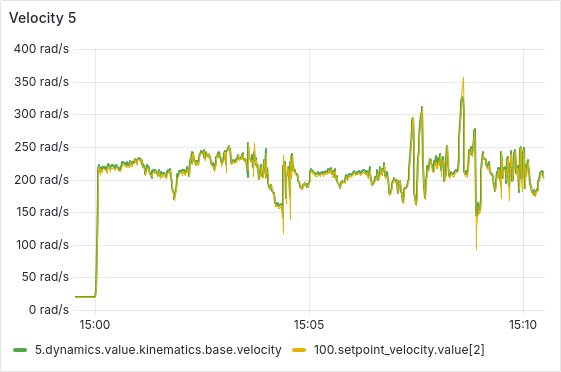
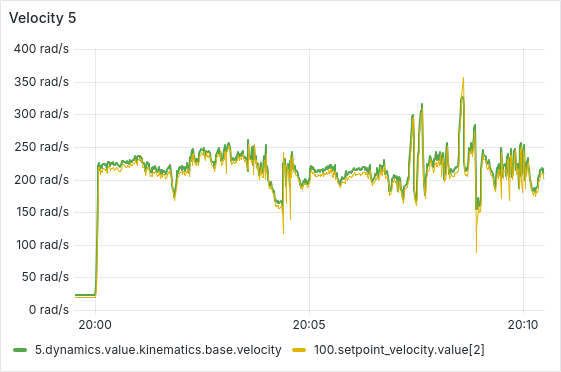
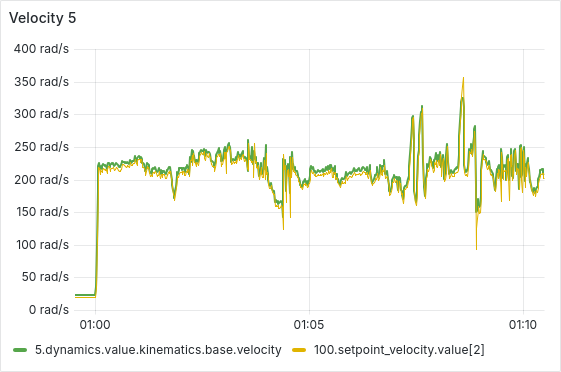
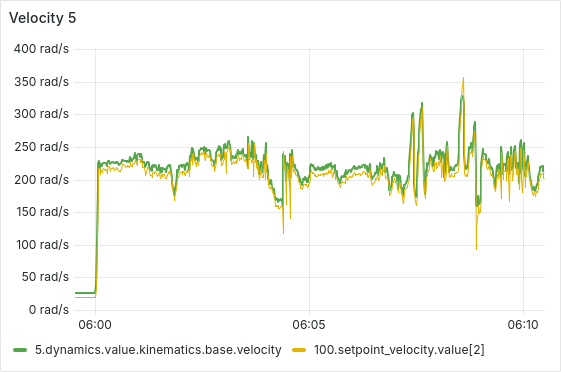
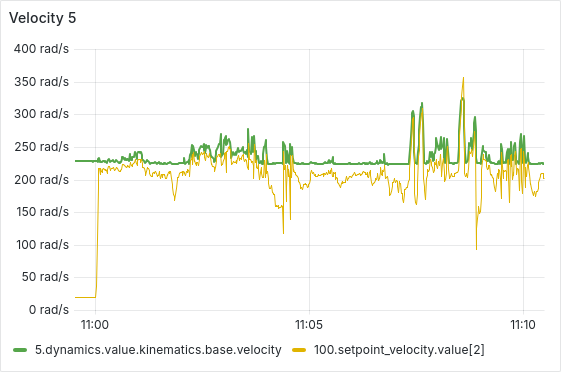
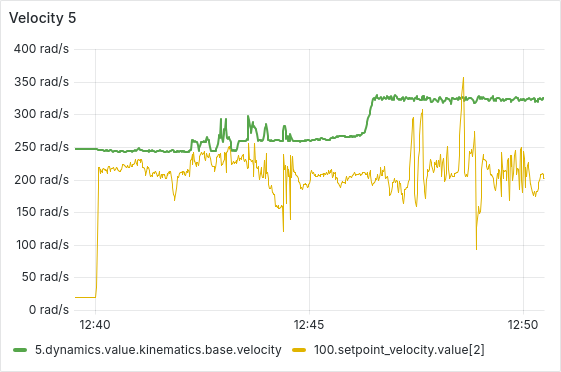
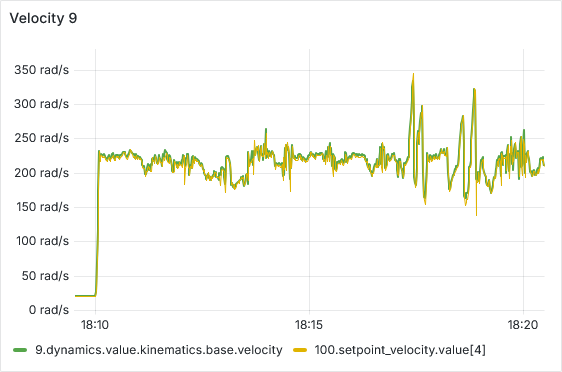
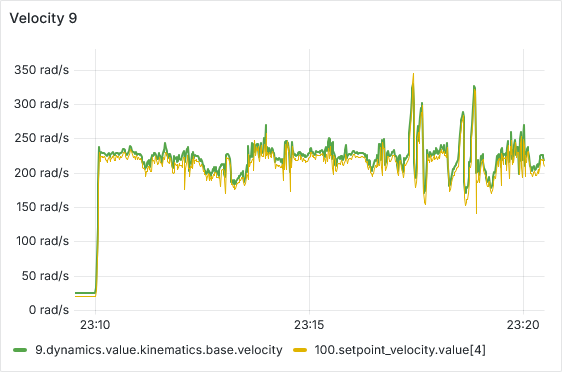
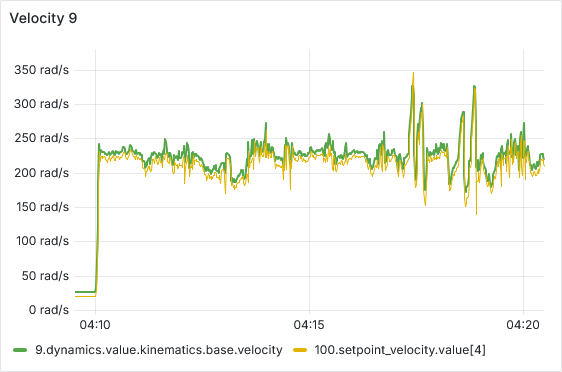
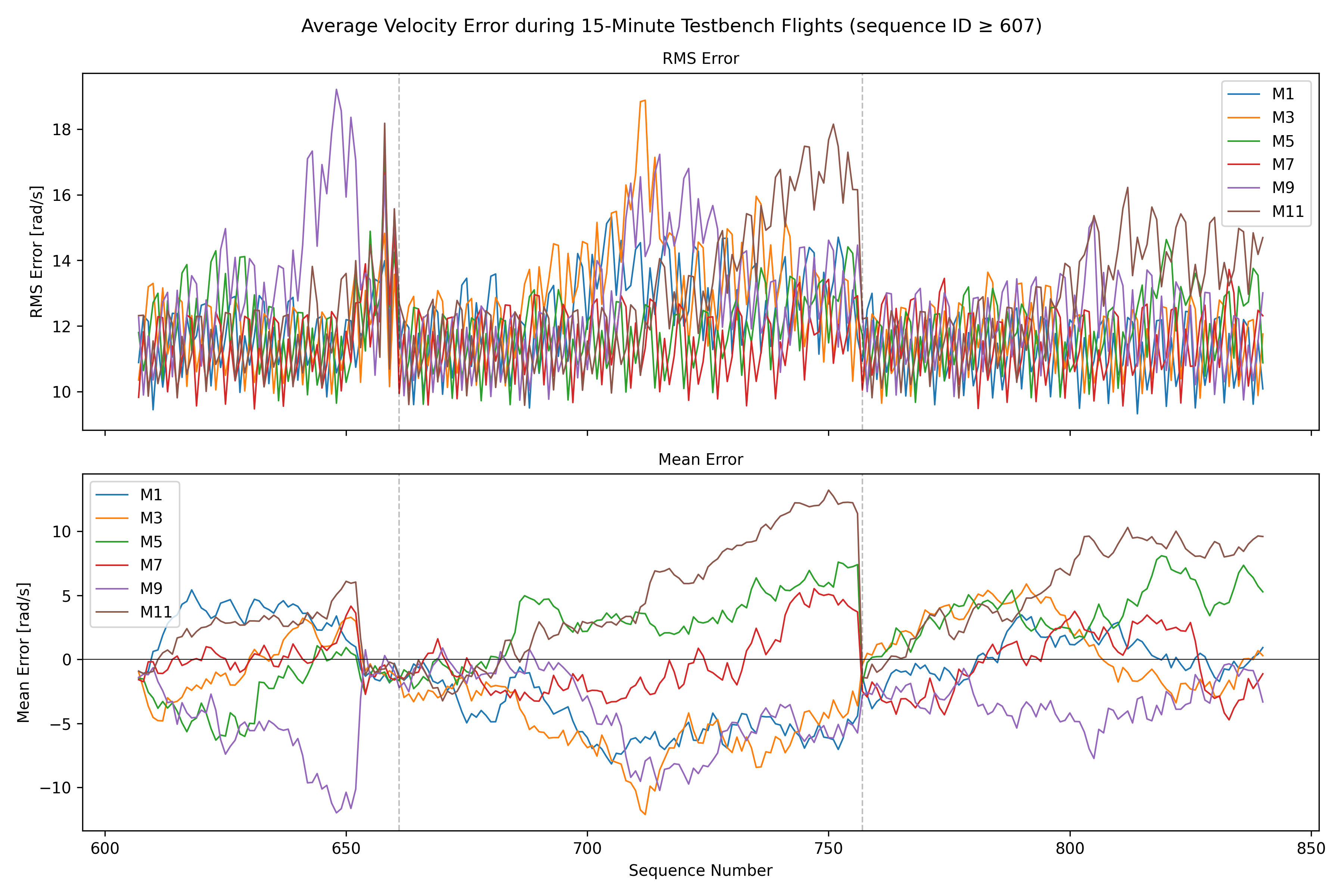
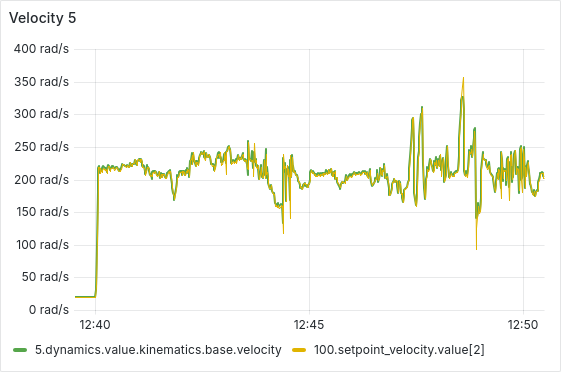
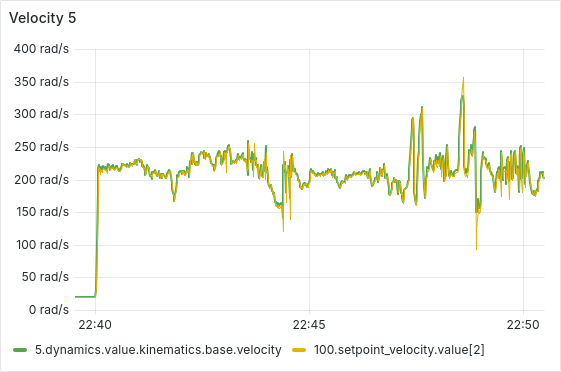
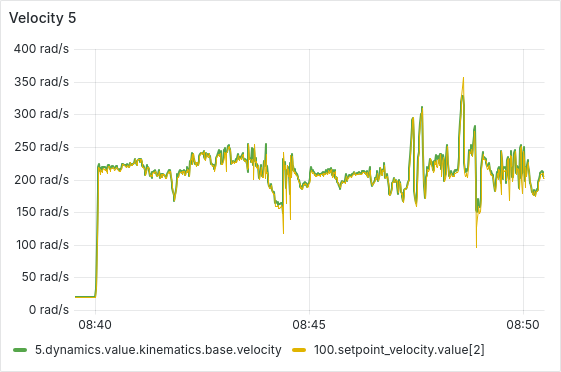
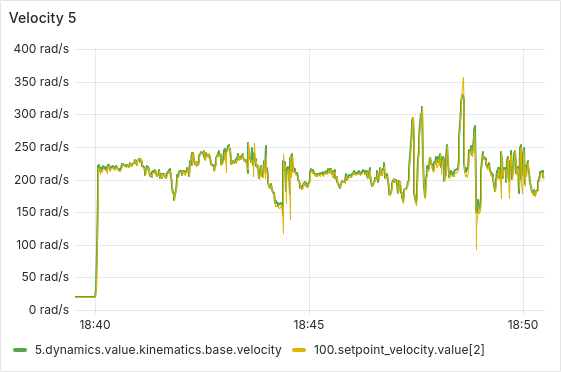
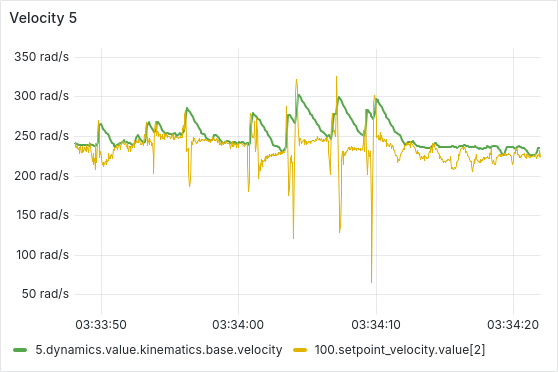
After a few hours of continuous operation, the velocity tracking starts getting worse, there seems to be a semi-constant offset between setpoint and actual velocity. After a few more hours, some ESCs start showing behavior where the velocity can’t go below a certain lower threshold, as is shown in the picture below. From there, this problem usually gets worse quickly, sometimes resulting in prolonged periods of full throttle (current-limited).
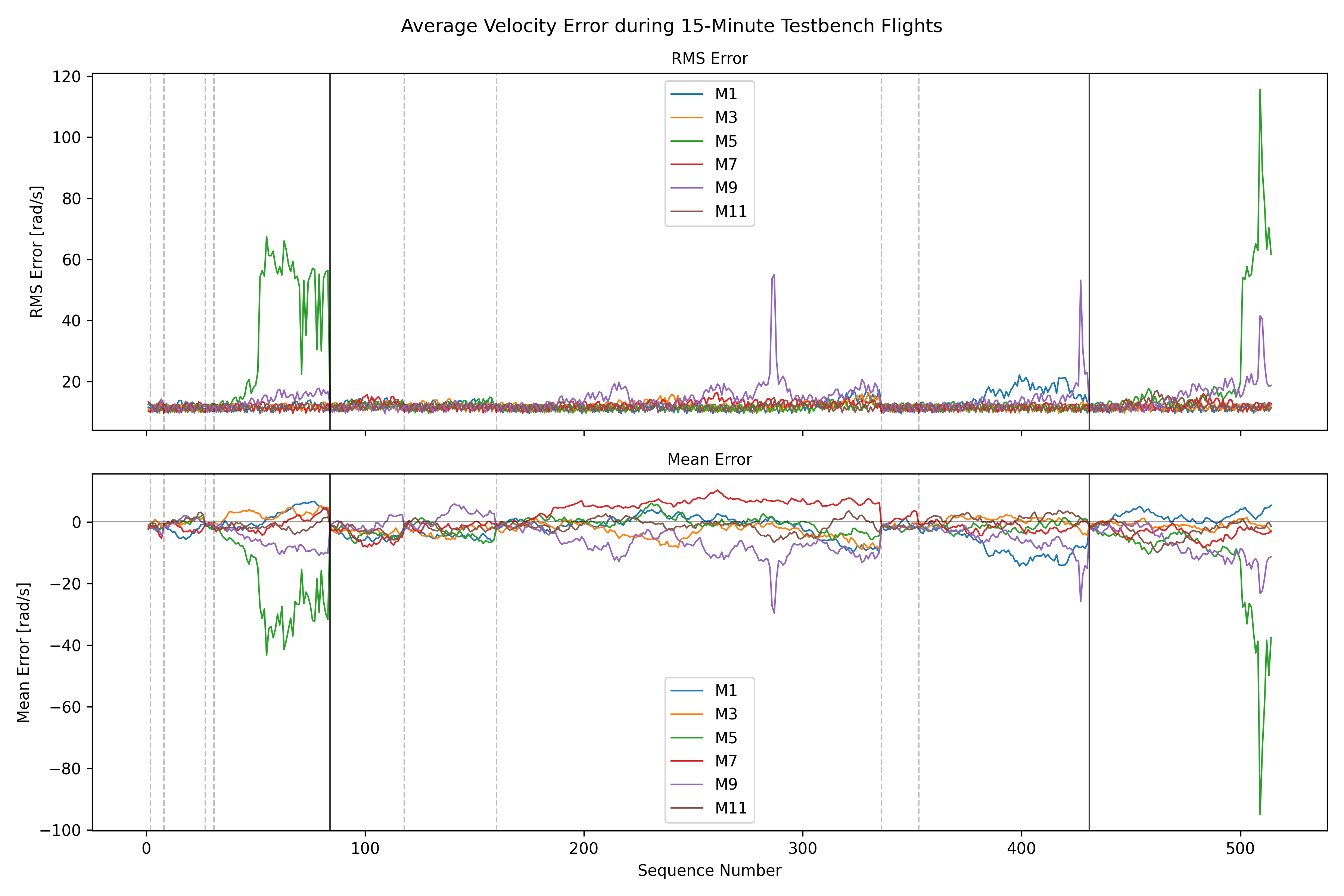
We have tested and observed this for around 130 hours, with the pattern emerging multiple times with different ESCs. Restarting the sequence seems to solve the immediate issue (dashed vertical lines in the plot below), a full reboot of the Telega firmware (solid black vertical lines) does not seem to have any additional effect.
This is not a known issue. The INDI controller has the integrator off per your config, and internally it is basically stateless otherwise. One thing that seems suspicious is that you have RCPWM control enabled without strong pull and no deadband:
In this setup, especially if you have anything plugged into the aux port, spurious control inputs are possible. Can you check if it’s possible to reproduce the issue with the aux port disabled completely?
This run also shows first signs of the same problem, even with the PWM input completely disabled. I have not yet observed the “setpoint clipping” state, but the offset is already noticeable.
I had to restart the test sequence this morning due to an unrelated issue, but I will continue trying to reproduce the fault sequence observed earlier.
Over the weekend I have not been able to reproduce the velocity runaway described above, so the issue might be related to the RCPWM input configuration.
The slowly accumulating velocity error is still very much a thing, though:
@finwood would it be possible to obtain the current and demand factor plots captured around the onset of the issue? I am having trouble reproducing it locally so far.
EDIT: Also it would help if you could check whether setting drive.velocity_ctl.2_indi.acceleration_pi[1] to a small positive value (the integral channel of the acceleration controller in the INDI) can mitigate the issue.
It appears that I virtually succeeded in reproducing the problem. It is related to a discrepancy between the estimated torque and the real torque due to motor parameter drift with temperature and other environmental factors. Investigation is still ongoing but I could really use additional telemetry data.
Sorry for the delay, I have been out sick the past few days.
I’ve exported a dataset for the run described in the first post above, from 2026-04-21 15:55:00+02:00 to 2026-04-22 14:20:00+02:00. The different Telega ports are available at https://telega-velocity-tracking.s3.fr-par.scw.cloud/2026-05-08/topic.parquet, along with the heartbeat of all devices in the network and the published velocity setpoint (a zubax.primitive.real16.Vector6.1.0).
$ mc ls -r scw/telega-velocity-tracking
[2026-05-08 12:04:11 UTC] 46MiB STANDARD 2026-05-08/compact.parquet
[2026-05-08 12:04:13 UTC] 70MiB STANDARD 2026-05-08/dq.parquet
[2026-05-08 12:04:05 UTC] 149MiB STANDARD 2026-05-08/dynamics.parquet
[2026-05-08 12:04:09 UTC] 29MiB STANDARD 2026-05-08/feedback.parquet
[2026-05-08 12:04:02 UTC] 4.6MiB STANDARD 2026-05-08/heartbeat.parquet
[2026-05-08 12:04:08 UTC] 85MiB STANDARD 2026-05-08/power.parquet
[2026-05-08 12:04:15 UTC] 32MiB STANDARD 2026-05-08/setpoint.parquet
[2026-05-08 12:04:10 UTC] 35MiB STANDARD 2026-05-08/status.parquet
[2026-05-08 12:04:14 UTC] 29MiB STANDARD 2026-05-08/temperature.parquet
[2026-05-08 12:17:18 UTC] 6.2GiB STANDARD duck.db
The complete dataset of all runs so far is additionaly available in the DuckDB file also present in the same S3 bucket: duck.db (6.2 GiB). The parquet files are flattened DSDL with two metadata columns (see below), the DuckDB file has been created with this load.sql (2.9 KB) script.
I will be back in the lab on Monday and will start another test run with a small drive.velocity_ctl.2_indi.acceleration_pi[1] value, I will update you on the results later that week.
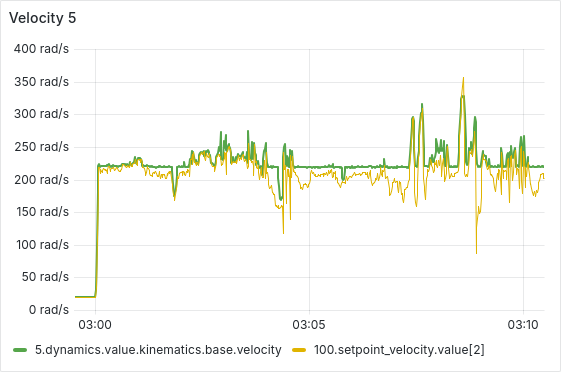
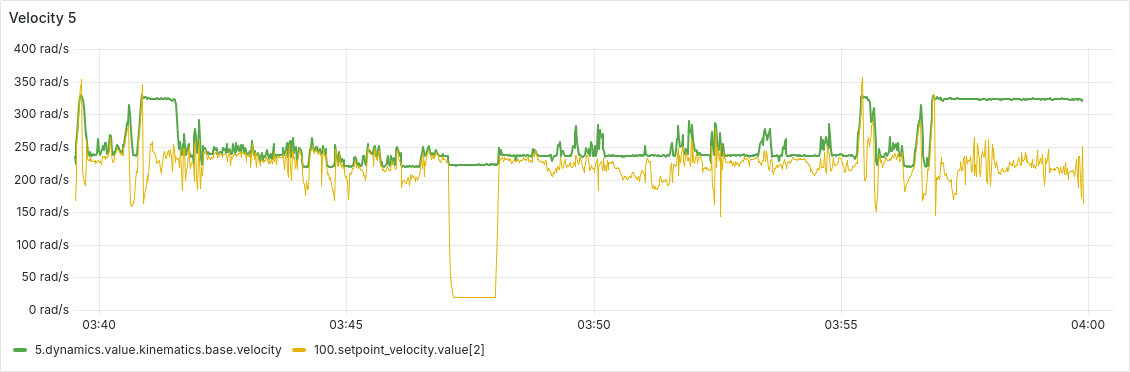
I have been able to reproduce the runaway (velocity?) controller issue, even with the AUX input disabled and a small positive I-gain in the INDI acceleration controller. The integral channel was able to compensate for the slowly accumulating velocity offset, but the runaway still occurred.
Shortly before the runaway, the “clipping” behavior is also still present. During that time, the motor seemed severely hindered in decelerating, as can be seen in the second-to-last plot at around 03:34:00. At 04:00:00 the test run was interrupted to prevent the controller from overheating.
Have you had any success in finding the root cause for this issue? Could it potentially escalate to critical condition within the first 2-3 hours, is there a fix planned? Right now this is manageable for us as we don’t fly for hours on end yet, but for a potentially tethered operation later this year this is a show stopper.
Please talk to me and help me plan, I wouldn’t want to have to start looking for a different ESC.
Apologies for the silence – all my time is spent on a different critical project so I have deprioritized every other matter temporarily.
Yes, we understand the root cause and can reproduce the problem. It is caused by the slight parameter drift that has a compounding effect due to the error integrating action of the INDI controller. The extent of the problem depends on the magnitude of the parameter drift (e.g., how much the temperature of the motor is changing) AND on the duration of the system operation (longer uptime → greater compounded drift).
You can immediately partially mitigate the problem by enabling some small integral term in the INDI acceleration controller settings, but it will only have a limited effect that will delay the onset of the problem but will not prevent it.
The correct fix requires a slight adjustment of the torque equation used in the INDI to make it DC bias insensitive. I already have the fix but it needs validation; I expect that I will be able to share the preview firmware with you tomorrow. Stay tuned!
Hi @pavel-kirienko, thank you for the firmware binary. Update worked well, no problems there. The software crashes when trying to spin up, though.
When publishing a finite (not NaN) velocity setpoint to the setpoint_velocity port, the drive enters drive mode shortly (VSSC 0x53), before crashing and rebooting into software update mode. The motors don’t move or budge during that sequence, the configuration is unchanged to the config.json (6.9 KB) linked above.
A concrete sequence:
Start a PNP server and node tracker instance (e.g. yakut monitor)
y pub -T0.1 99:zubax.primitive.real16.Vector6.1.0 "[nan, 0, nan, 50, nan, 100]"